

Concordances and Inverted Indices for Faster Retrieval
Leverage the mechanics of search engines for instant retrieval of your suff.


You’re getting this issue on a Sunday, the day of tidying up for most of us non-tech billionaires. For lack of a better example, let’s say you’re sorting your collection of VHS cassettes. It’s a soothing, almost meditational experience, but we can kill two birds with one stone by doing what search engines do to double the ROI of this activity.
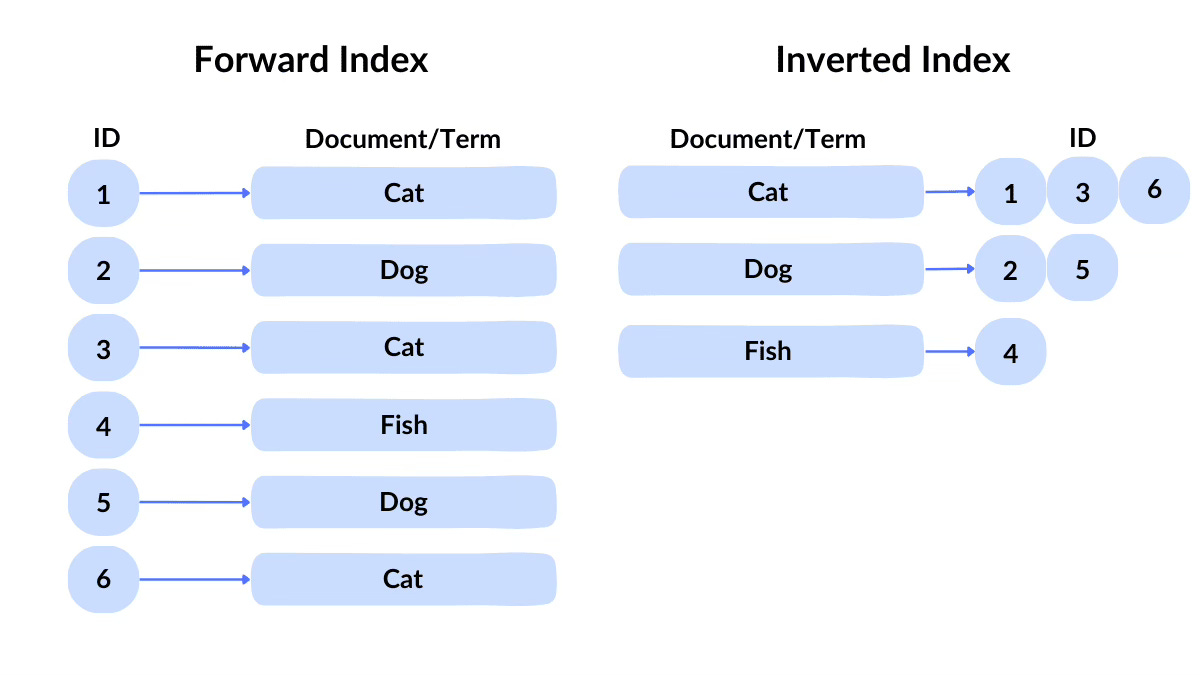
Whenever you sort the tapes by genre or alphabetically, you create the so-called “forward index.” This lets you quickly retrieve the necessary cassette when someone suggests watching “The Godfather.” Since it’s conveniently stored as “Godfather, The,” you skip to “G” and start looking towards the middle of the array. Retrieving the movie by a known attribute, such as its title in this example, becomes a rapid and computationally inexpensive operation.
But what if someone suggests to watch a mafia-related psychological drama? There’s no external attribute of “The Godfather” that’d allow for a quick retrieval. If you didn’t know any of the movies on the shelf, you’d had but one option: to watch all of the films from left to right, then pick the ones that correspond to the request. If, on top of that, like a machine, you were amnesiac, the next time someone would ask for the same recommendation, you’d have to repeat the entire operation. Needless to say, this is time-consuming and computationally prohibitive.
To be able to retrieve the necessary cassette(s), you’d have to do what search engines do: create the so-called “inverted index“, sometimes also called a “postings list”, “postings file”, or “inverted file”.
When you walk into a library, you use the librarian as a search engine and ask for a book recommendation on topics X, Y, or Z. The librarian, in his turn, uses the part of the brain that stores information on his reading history as an inverted index. Your question gets dissected into meaningful words by dropping auxiliary filler words, such as “why”, “and”, “or”, etc. and gets bundled with other semantically or linguistically related terms. So, a query such as “I’m looking for books about note-taking and personal knowledge management.” probably becomes an array of keywords like “notes”, “note-taking”, “personal knowledge management”, “knowledge management”, “PKM”, “notebooks”, “Tools for Thought”, “Cornel Notes”, “commonplace books”, “Zettlekasten”, “Niklas Luhmann”, “
”, “”, “”, “Building the Second Brain”, “Tiny Experiments”, etc. The more well-read the librarian, the richer his inverted index.Therefore, as seen in the figure above, such an “inverted index” is the opposite of a “forward index” and is the cornerstone of search engines we take for granted nowadays.
Of course, there’s much more to a sophisticated search engine than that, such as searching for words near other words, latent semantic indexing, which is the premise that words from the same context tend to have similar meaning, bilingual concordance, aligned parallel text, etc. But think of all of the bells and whistles of modern search engines as incremental improvements on this simple, fundamental idea. After all, everything genius is mostly dead-simple.
Although the example I used was video cassettes, you can substitute them with any information-carrying medium, especially your knowledge and notes.
Concordance
The idea of an inverted index does not originate from the world of IT. Computer scientists often build on the shoulders of giants, some of whom lived and invented long before electronics were even a thing. It’s like reading a book based on a movie based on a book based on a film, a lucrative, hence very popular cycle abused by the media industry.
Before we were given the first online search engine (which wasn’t Google), there was an analogue equivalent of one: concordance.
Concordance is an alphabetical list of principal (not auxiliary) words used in a book or body of work, listing their position and context. It was a precursor to digital inverted indices in the publishing world and is also widely used in linguistics.
Just like building an inverted index requires a lot of computational resources and storage, creating analogue concordances was prohibitively resource-intensive. It could take hundreds of clerks and decades to complete. This is why such analogue concordances were only made for true bestsellers, such as the Bible, the Qur’an, and the likes of it.
Suppose you use digital tools for thought that support fuzzy search (a search where “mom” also equals “mum”, “mam”, or “mother”), then creating and maintaining the inverted index is done for you behind the curtains. But if you go analogue or want to accept the intellectual challenge of recreating a paper-based search engine, you can use the wisdom of our ancestors to assist you in doing so. Many swear by this manual approach even today. The whole Zettelkasten movement praises the so-called reference notes, also called literature notes, when they’re nothing but concordances for specific source material with keywords only relevant to you.
Look at the example given by
in his brilliant new “A System for Writing“1.
Looking at the figure above, you can tell that a typical (improved) Zettelkasten reference, or literature note, is a list of pointers that connects keywords (rightmost column) to places in the content annotated (leftmost column). Notice how this note does not include all keywords but only those relevant to the note-maker, making it a personal concordance file. Also, notice how the keywords “psych” or “feeding” appear several times as we read the book.
Another essential part of the above example is the central column. It contains additional commentary explaining the reason for this entry's existence. This is a characteristic of handmade concordances. Besides acting as indices, they’re enriched with context, annotations, commentary, definitions, or topical cross-indexing. It’s highly personal and context-specific. I wonder how much of it could be generated by AI these days, if at all—food for thought.
A significant boost can be given to indexing using “topical concordance”. This means an index could contain a word that doesn’t necessarily appear in the original text. Sophisticated technologies powering modern search engines perform this enrichment for you either mathematically or statistically through mechanisms such as contingency tables or, lately, by leveraging artificial intelligence. Of course, you can (and should) do so in the analogue realm. The latter's benefit is that you alone can develop relationships between words that make sense to you. A machine can only approximate the relevance of such connections.
OK, But at What Cost?
We’ve previously discussed that we’re locked into an iron triangle, and corners had to be cut because one can’t have a cake and eat it, too. Creating a search engine is no exception. But, as always, some sacrifices might not feel like ones, depending on the goals and available tools.
An inverted index is designed to retrieve information based on a fuzzy full-text search as quickly as possible. To gain in retrieval speed, we’ll have to sacrifice something else. In this case, it’ll be the upfront prep work. Indeed, more work has to be done upfront to allow for the primary benefit, the fast fuzzy document retrieval. This processing can be done Just-In-Time (JIT) when you add a document to the collection or on a schedule (this Sunday, for example).
You could also decide how thorough your inverted index would be. We mainly distinguish between a record-level index and a word-level index.
The former links a specific word to a document, essentially saying the word “apple” can be found in documents A and X. The figure above is an example of such simple concordance.
The latter goes further by linking words and numbers to documents and drilling down deeper to annotate every entry with the position of this word within the related document.
So, a word-level index entry would be stored as the word “apple” can be found in document A, page 2, paragraph 3, position 56, as well as document A, page 4, paragraph 1, position 17, and document X, page 60, paragraph 2, position 7.
Take reading the Bible for an example. Preachers would refer their audience to a specific passage of the holy text through the word-level index: “Refer to Numbers 13:12…” but the record-level index would refer them to the Bible in its entirety.
This makes a word-level index a superset of the record-level index, and one might wonder why we even need an “inferior” record-level index. Once again, the answer is that nothing is free, and creating a word-level index is significantly costlier in terms of the required effort and the necessary storage to keep the extra pointers within the content of each document. If the word “apple” appears 100 times within the document, you’ll have 100 times more to do and store than a quick, single record-level entry. If you don’t need the minutiae of super-targeted pointers, you’re much better off keeping it simple.
Manual concordance creation is one of the best ways to intimately connect to your knowledge. It’s the foundation of many PKM frameworks. Of course, this requires periodic revision of your notes, but the life-long benefits of such activity can’t be understated. So, sharpen your knowledge knives and impress folks with your referencing, like librarians. Librarians do impress you, right?
Doto, B. (2024). A System for Writing: How an Unconventional Approach to Note-making Can Help You Capture Ideas, Think Wildly, and Write Constantly.